Intel
®
Fortran Compiler 10.0, Professional and Standard Editions, for Linux*
 |
 Intel®
Fortran Compiler Professional Edition offers the best support for
creating multi-threaded applications. Only the Professional Edition
offers the breadth of advanced optimization, multi-threading, and
processor support that includes automatic processor dispatch,
vectorization, auto-parallelization, OpenMP*, data prefetching, loop
unrolling, substantial Fortran 2003 support, and an optimized math
processing library.
The Professional Edition combines a high performance compiler with
Intel® Math Kernel Library (Intel® MKL). While this
library is available separately, the Professional Edition creates a
strong foundation for building robust, high performance parallel code
at significant price savings.
The Standard Edition compiler has the same performance and features as
the Professional Edition compiler, but does not include Intel MKL.
Cluster OpenMP* for Intel Fortran Compiler for Linux is also available
to provide all the functionality of the Intel Fortran Compiler for
Linux, plus a simple means of extending OpenMP parallelism to 64-bit
Intel® architecture-based clusters.
Product
Brief [PDF 696KB]
The
Intel Fortran Compiler for Linux delivers rapid development and winning
performance for the full range of Intel® processor-based
platforms. It is a full-language Fortran 95 compiler with many features
from the Fortran 2003 standard, plus a wide range of popular
extensions. Automatically optimize and parallelize software to take
best advantage of multi-core Intel processors, including dual-core
mobile, desktop, and enterprise platforms.
Performance
Intel Fortran Compiler Professional Edition lets you choose the tools
that get most out of multi-core processors by combining the Fortran
compiler and its built-in optimization, threading, and security
capabilities with a highly optimized math library that simplifies the
introduction of robust, scalable, multi-threaded math functions.
Advanced Optimization Features
Software compiled using the Intel Fortran Compiler for Linux benefits
from advanced optimization features, a few of which are explained
briefly here, with links to more complete descriptions:
- Multithreaded
Application Support, including OpenMP and
auto-parallelization for simple and efficient software threading.
- Auto-vectorization
parallelizes code to utilize the Streaming SIMD Extensions (SSE)
instruction set architectures (SSE, SSE2, SSE3, SSSE3, and SSE4) of our
latest processors.
- High-Performance
Parallel Optimizer (HPO) restructures and optimizes
loops to ensure that auto-vectorization, OpenMP, or
auto-parallelization best utilizes the processor’s
capabilities for cache and memory accesses, SIMD instruction sets, and
for multiple cores. This revolutionary capability, new for 10.0,
combines vectorization, parallelization and loop transformations into a
single pass which is faster, more effective and more reliable than
prior discrete phases.
- Interprocedural
Optimization (IPO) dramatically improves
performance of small- or medium-sized functions that are used
frequently, especially programs that contain calls within loops. The
analysis capabilities of this optimizer can also give feedback on
vulnerabilities and coding errors, such as uninitialized variables or
OpenMP API issues, which cannot be detected as well by compilers which
rely strictly on analysis by a compiler front-end.
- Profile-Guided
Optimization (PGO) improves application performance
by reducing instruction-cache thrashing, reorganizing code layout,
shrinking code size, and reducing branch mispredictions.
- Optimized
Code Debugging with the Intel® Debugger
improves the efficiency of the debugging process on code that has been
optimized for Intel architecture.
The
Intel Fortran Compiler for Linux builds on a winning foundation.
Position yourself to create next-generation software, for
next-generation hardware.
| What’s
new |
Benefit to you |
| More Fortran
2003 features |
C Interoperability
features make it easier to develop mixed-language applications.
Asynchronous I/O enhances performance of applications which read and
write large files. See the compiler Release Notes for a full list of
supported Fortran 2003 features.
|
Improved
Performance and Threading
- New Parallel/Loop Optimizer (HPO)
|
Better application
performance for computationally intensive applications such as
graphics/digital media, financial modeling, and high-performance
computing for threaded and non-threaded applications. Our new High
Performance Parallel Optimizer, HPO, offers an improved ability to
analyze, optimize, and parallelize more loop nests.
|
Security
Checking and Diagnostics
- GNU Mudflap
- Static Verifier for buffer overflow
- OpenMP* API verification.
|
Ability to create code
that is less susceptible to security vulnerabilities, such as buffer
overflow. The diagnostics are very helpful for novice and expert users
for catching common coding errors, from uninitialized variables to
mismatched dummy and actual arguments to OpenMP API coding issues.
|
| Optimization
Reports |
More detailed
optimization diagnostics for users who want to use our advanced
optimizations to help the compiler do a better job at tuning their
applications. The new VTune™ Analyzer 9.0 can filter
optimization reports to help guide optimization efforts. |
Support for
the Latest Multi-Core Processors
The Intel Fortran Compiler provides optimization support for the very
latest multi-core Intel processors, including:
- Intel® Core™2 Duo
processor
- Intel® Core™2 Quad
processor
- Quad-Core Intel® Xeon®
processor 5300 series
- Dual-Core Intel® Xeon®
processor 3000 series
- Dual-Core Intel® Xeon®
processor 5000 series
- Dual-Core Intel® Xeon®
processor 7000 series
- Dual-Core Intel® Itanium®
2 processor
|
Intel®
compilers future-proof your investment with assurances that they
rapidly provide world-class support for each successive generation of
processors. That's a key advantage in a world where new hardware
platforms come to market with awesome speed.
Support for auto-parallelization and OpenMP enable you to create
optimized, multithreaded applications that take full advantage of
multi-core processing features to deliver outstanding performance.
|
| Professional
Edition |
Includes not only the
advanced capabilities of the compiler, but also the Intel Math Kernel
Library (Intel MKL) with highly optimized functions for math
processing.
|
| Advanced Optimization Features in Depth |
This
section gives detailed descriptions of the compiler’s
advanced optimization features.
Multithreaded
Application Support
OpenMP and auto-parallelization help convert serial applications into
parallel applications, allowing you to take full advantage of
multi-core technology like the Intel® Core™ Duo
processor and Dual-Core Intel Itanium 2 processor, as well as symmetric
multiprocessing systems:
- OpenMP is the industry
standard for portable multithreaded application development. It is
effective at fine-grain (loop-level) and large-grain (function-level)
threading.
OpenMP directives are an easy and powerful way to convert serial
applications into parallel applications, enabling potentially big
performance gains from parallel execution on multi-core and symmetric
multiprocessor systems.
- Auto Parallelization
improves application performance on multiprocessor systems by means of
automatic threading of loops. This option detects parallel loops
capable of being executed safely in parallel and automatically
generates multithreaded code.
Automatic parallelization relieves the user from having to deal with
the low-level details of iteration partitioning, data sharing, thread
scheduling, and synchronizations. It also provides the performance
benefits available from multiprocessor systems and systems that support
Hyper-Threading Technology.
For more information on multithreaded application support, visit
Intel's Threading
Developer Center.
High
Performance, Parallel Optimizer (HPO)
This revolutionary capability, new for 10.0, combines automatic
vectorization, automatic parallelization and loop transformations into
a single pass which is faster, more effective and more reliable than
prior discrete phases.
HPO optimizes and restructures program loops to ensure that
auto-parallelization, OpenMP and auto-vectorization occur smoothly in
conjunction with each other. HPO’s optimization technology
utilizes a unique cost-benefit analysis to make the right optimization
decisions for the given program and loop structure. It will perform
many transformations such as loop unrolling, peeling, interchange,
splitting, etc., as well as other optimizations to ensure the
processor’s cache architecture, SIMD instruction set, and
multiple cores are well utilized. These loop transformation are done
automatically so that manual code changes are not required.
Automatic
Vectorizer
Vectorization automatically parallelizes code to maximize underlying
processor capabilities. This advanced optimization analyzes loops and
determines when it is safe and effective to execute several iterations
of the loop in parallel by utilizing MMX™, SSE, SSE2, and
SSE3 instructions. Figure 1. is a graphical representation of a
vectorized loop that shows four iterations computed with one SSE2
operation.
Use vectorization to optimize your application code and take advantage
of these new extensions when running on Intel processors. Features
include support for advanced, dynamic data alignment strategies,
including loop peeling to generate aligned loads and loop unrolling to
match the prefetch of a full cache line.
 Figure 1. The Vectorizer in action
Figure 1. The Vectorizer in action
Interprocedural optimization (IPO) can dramatically improve application
performance in programs that contain many small- or medium-sized
functions that are frequently used, especially for programs that
contain calls within loops. This set of techniques, which can be
enabled for automatic operation in the Intel compilers, uses multiple
files or whole programs to detect and perform optimizations, rather
than focusing within individual functions.
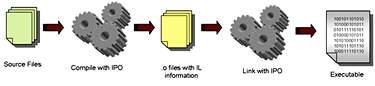
Figure
2. The interprocedural optimization process.
The IPO process, shown in Figure 2, first requires that source files
are compiled with the IPO option, creating object (.o) files that
contain the intermediate language (IL) used by the compiler. Upon
linking, the compiler combines all of the IL information and analyzes
it for optimization opportunities. Typical optimizations made as part
of the IPO process include procedure inlining and re-ordering,
eliminating dead (unreachable) code, and constant propagation, or the
substitution of known values for constants. IPO enables more aggressive
optimization than what is available at the intra-procedural level,
since the added context of multiple procedures makes those
more-aggressive optimizations safe.
The analysis capabilities of IPO can also give feedback on
vulnerabilities and coding errors, such as uninitialized variables,
which cannot be detected as well by compilers which rely strictly on
analysis by a compiler front-end.
Profile-Guided
Optimization (PGO)
The Profile-guided optimization (PGO) compilation process enables the
Intel C++ compiler to take better advantage of the processor
microarchitecture, more effectively use instruction paging and cache
memory, and make better branch predictions. It improves application
performance by reorganizing code layout to reduce instruction-cache
thrashing, shrinking code size and reducing branch mispredictions.
PGO is a three-stage process, as shown in Figure 3. Those steps include
1) a compile of the application with instrumentation added, 2) a
profile-generation phase, where the application is executed and
monitored, and 3) a recompile where the data collected during the first
run aids optimization. A description of several code size influencing
profile-guided optimizations follows:
- Basic block and function ordering —
Place frequently-executed blocks and functions together to take
advantage of instruction-cache locality.
- Aid inlining decisions — Inline
frequently-executed functions so the increase in code size is paid in
areas of highest performance impact.
- Aid vectorization decisions —
Vectorize high trip count and frequently-executed loops so the increase
in code size is mitigated by the increase in performance.
Optimized
Code Debugging with the Intel Debugger
The Intel Debugger enables optimized code debugging (i.e., debugging
code that has been significantly transformed for optimal execution on
specific hardware architecture). Intel compilers produce
standards-compliant debug information for optimized code debugging that
is available to all debuggers that support Intel compilers. The Intel
Debugger supports multi-core architectures by enabling debugging of
multithreaded applications, providing the following related
capabilities:
- An all-stop/all-go execution model (i.e., all
threads are stopped when one is stopped, and all threads are resumed
when one is resumed)
- List all created threads
- Switch focus between threads
- Examine detailed thread state
- Set breakpoints (including all stop, trace and
watch variations) and display a back-trace of the stack for all threads
or for a subset of threads
- The built-in GUI provides a thread panel (on
the Current Source pane) that activates when a thread is created, and
that allows an operator to select thread focus and display related
details
The recently enhanced GNU Project Debugger (GDB debugger) can also be
used for parallel applications. For additional information, please
refer to the Intel
Debugger Technical White Paper.
| Compatibility and Flexibility |
Standards
Compliance and Broad Compatibility
The Intel Fortran Compiler 10.0 for Linux fully supports the Fortran 95
language standard, as well as the previous standards Fortran 90,
Fortran 77 and Fortran IV. It also includes many features from the
Fortran 2003 language standard, as well as numerous popular language
extensions. Significant supported language extensions include:
- Quadruple precision REAL data type REAL(16)
- STRUCTURE, RECORD, UNION, MAP syntax for
user-defined types
- Directives and functions to enhance
mixed-language application development
- Binary stream I/O
For a complete list of language features, see the product documentation.
The Intel Fortran Compiler 10.0 for Linux also enhances programmer
productivity with features such as:
- Run-time array and string bounds checking
- Cross-file procedure interface checking
- Run-time uninitialized variable detection
- Error traceback with file name and line number
Winning Performance across Application Domains
The Intel Fortran Compiler for Linux delivers exceptional performance,
usability, and business advantages to a wide variety of software
markets.
 Next-generation data-intensive application
developers
Next-generation data-intensive application
developers benefit from dramatic performance optimizations
using the Intel compilers to decrease latency and processing times,
while also allowing software architects to add additional features
without unacceptable impacts to performance.
 Scientific,
research, and related applications Scientific,
research, and related applications benefit from fast compile
times, high-performance execution, and solid technical support.
Numerically intensive software can make excellent use of the
parallelism in Intel processor-based platforms.
With
the purchase of an Intel Fortran Compiler, you will receive one year of
technical support and product updates from Intel® Premier
Support, our interactive issue management and communication web site.
This premium support service allows you to submit questions, download
product updates, and access technical notes, application notes, and
other documentation. For more information, visit the Intel®
Registration Center.
Back to top
This
section provides system requirements to develop applications for three
different hardware platforms, which are described below.
Processor Terminology
Intel compilers support three platforms: general combinations of
processor and operating system type. This section explains the terms
that Intel uses to describe the platforms in its documentation,
installation procedures and support site.
IA-32 architecture - IA-32 (Intel
Architecture, 32-bit) architecture refers to systems based on 32-bit
processors supporting at least the Pentium® II instruction set,
(for example, Intel® Core™ architecture-based
processor or Intel® Xeon® processor), or processors
from other manufacturers supporting the same instruction set, running a
32-bit operating system ("Linux x86").
Intel® 64 architecture - Intel
64 architecture (formerly Intel® EM64T) refers to systems based
on IA-32 architecture-based processors which have 64-bit architectural
extensions, (for example, Intel® Core™2 processor
family or Intel Xeon processor), running a 64-bit operating system
("Linux x86_64"). If the system is running a 32-bit version of the
Linux operating system, then IA-32 architecture applies instead.
Systems based on the AMD* Athlon64* and Opteron* processors running a
64-bit operating system are also supported by Intel compilers for Intel
64 architecture-based applications.
IA-64 architecture - Refers to systems
based on the Intel Itanium 2 processor running a 64-bit operating
system.
Native and Cross-Platform Development
The term "native" refers to building an application that will run on
the same platform that it was built on, for example, building on IA-32
architecture to run on IA-32 architecture. The term "cross-platform" or
"cross-compilation" refers to building an application on a platform
type different from the one on which it will be run, for example,
building on IA-32 architecture to run on IA-64 architecture. Not all
combinations of cross-platform development are supported, and some
combinations may require installation of optional tools and libraries.
The following list describes the supported combinations of compilation
host (system on which you build the application) and application target
(system on which the application runs).
- IA-32 architecture host - Supported target:
IA-32 architecture
- Intel 64 architecture host - Supported targets:
IA-32 and Intel 64 architectures
- IA-64 architecture host - Supported target:
IA-64 architecture
Note: Development for a target different
from the host may require optional library components to be installed
from your Linux Distribution.
Note: Cluster OpenMP for Intel Compilers
for Linux is a separately licensed feature and has different system
requirements from that of the compilers. Please refer to the product
website for further details.
Requirements
to develop IA-32 architecture-based applications
|
Component
|
Minimum
|
Recommended
|
| Processor |
A system based on an
IA-32 architecture-based processor (minimum 450 MHz), Intel 64
architecture-based processor, or a system based on an AMD Athlon or AMD
Opteron processor. |
- Intel Core Duo processor
- Intel® Pentium® 4
processor
- Intel® Pentium® D
processor
- Intel Xeon processor
|
| RAM |
256MB
|
512MB
|
| Disk Space |
100 MB of disk space,
plus an additional 200 MB during installation for the download and
temporary files |
NA
|
| Operating
System |
Linux system with glibc
2.2.4, 2.2.5, 2.2.93, 2.3.2 , 2.3.3, 2.3.4, or 2.3.5 and the 2.4.X or
2.6.X Linux kernel as represented by the following distributions.
Note: Not all distributions listed
are validated and not all distributions are listed.
- Fedora* Core 6
- Mandriva* Linux 2007
- Red Flag* DC Server 5.0
- Red Hat Enterprise Linux* 3, 4, 5
- SUSE LINUX Enterprise Server* 9, 10
- TurboLinux* 10
|
NA
|
| Other
Software |
Linux Developer tools
component installed, including gcc 3.2 or later, g++ and related tools.
Linux component compat-libstdc++ providing libstdc++.so.5 |
NA
|
Requirements
to develop applications for processors that support Intel 64
Architecture or for AMD Opteron processors
|
Component
|
Minimum
|
Recommended
|
|
Processor
|
Intel processor with
Intel 64 architecture |
Intel Core 2 processor
family
Intel Xeon processor
|
| RAM |
256MB
|
512MB
|
| Disk Space |
300 MB free hard disk
space, plus an additional 300 MB during installation for download and
temporary files.
100 MB of hard disk space for the virtual memory paging file. Be sure
to use at least the minimum amount of virtual memory recommended for
the installed distribution of Linux. |
NA
|
| Operating
System |
Linux system with glibc
2.2.93, 2.3.2, 2.3.3, 2.3.4 or 2.3.5 and the 2.4.X or 2.6.X Linux
kernel as represented by the following Linux distributions, running in
64-bit mode.
Note: Not all distributions listed
are validated and not all distributions are listed.
- Fedora Core 6
- Mandriva Linux 2007
- Red Flag DC Server 5.0
- Red Hat Enterprise Linux 3, 4, 5
- SGI ProPack 4, 5
- SUSE LINUX Enterprise Server 9, 10
- TurboLinux 10
|
NA
|
| Other
Software |
Linux Developer tools
component installed, including gcc 3.2 or later, g++ and related tools.
Linux component compat-libstdc++ providing libstdc++.so.5 |
NA
|
Requirements
to develop IA-64 architecture-based applications
|
Component
|
Minimum
|
Recommended
|
| Processor |
Itanium 2 processor |
NA
|
| RAM |
512MB
|
1GB
|
| Disk Space |
150 MB of disk space,
plus an additional 200 MB during installation for the download and
temporary files. |
NA
|
| Operating
System |
Linux system with glibc
2.2.4, 2.2.93, 2.3.2, 2.3.3 or 2.3.4 and the 2.4.X or 2.6.X Linux
kernel as represented by the following distributions.
Note: Not all distributions listed
are validated and not all distributions are listed.
- Red Flag DC Server 5.0
- Red Hat Enterprise Linux 3, 4, 5
- SGI ProPack 5
- SUSE LINUX Enterprise Server 9, 10
- TurboLinux 10
|
NA
|
| Other
Software |
Linux Developer tools
component installed, including gcc 3.2 or later, g++ and related tools.
Linux component compat-libstdc++ providing libstdc++.so.5 |
We recommend using
binutils 2.14 or later, especially if using shared libraries as there
are known issues with binutils 2.11 |
Notes:
The above lists of processor model names are not exhaustive - other
processor models correctly supporting the same instruction set as those
listed are expected to work. Please contact Intel® Premier
Support if you have questions regarding a specific processor model.
Compiling very large source files (several thousands of lines) using
advanced optimizations such as -O3, -ipo and -openmp, may require
substantially larger amounts of RAM.
Some optimization options have restrictions regarding the processor
type on which the application is run. Please see the documentation of
these options for more information.
|
|